
AT A GLANCE
Ever wondered what makes AI solutions truly smart? How does this technology make good decisions or accurate predictions on our behalf? No, it does not happen by magic. AI is only as good as the data we use to train it. But it cannot be just any data. Raw records must be transformed into meaningful information. Outstanding results simply come from what happens behind the scenes: data labelling and annotation. But what exactly are they? How do they work? And how can you tell them apart and use them more effectively? Read on to find out.
Introduction
We increasingly admire and adopt AI for its unmatched speed and analytical power, delivering insights once beyond human reach and capability. However, behind the scenes stand two unsung heroes: data labelling and annotation services. These are the make-or-break factors in most AI project success stories, typically operating silently in the background. Yet their impact is anything but minor. They perform the real magic, helping overcome one of AI’s fundamental limitations: the lack of natural, human-like understanding needed to function independently.
Data labelling and annotation quietly but critically power intelligent systems by providing structured, meaningful data that algorithms can recognise, learn from, and act upon effectively. This is made possible by skilled people’s often mundane yet continuous work, supported by advanced AI-assisted tools and robust project management. Nothing less, nothing more.
Why Teaching AI Matters: From Raw Data to Real Understanding
Simply put, artificial intelligence is not smart from the start. Its true strength does not lie in raw computation alone. From the beginning, it does not understand our world, intentions, or the subtle context behind personal communication. Therefore, we must teach and guide it to meet our expectations and operate meaningfully within our environment. This is where data labelling and annotation come in.
They ensure knowledge and context, essential for algorithms to identify patterns accurately, reduce bias, interpret language, and recognise relationships. Only then does the investment truly pay off, and AI ultimately fulfils our intended purpose through its implementation.
Consequently, the data annotation and labelling market is growing fast. It was estimated to achieve $1.7 billion in 2024 and is expected to reach $2.26 billion in 2025, increasing at about 32.5% per year. By 2029, it could even reach $7 billion, continuing its rapid expansion (Source: Research and Markets).

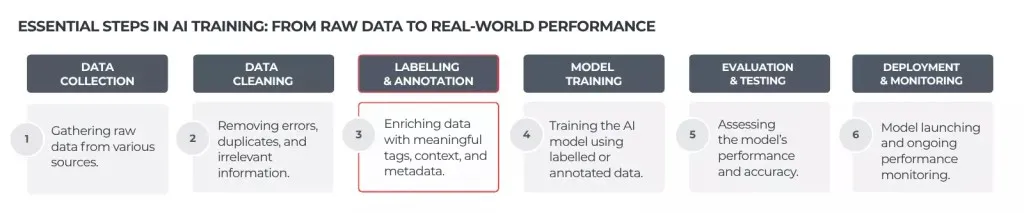
Let’s now dive deeper into data labelling and annotation, uncovering their distinct roles, their combined significance, and how they empower AI to achieve peak performance together.
What is Data Labelling
Data labelling is the initial step of the AI-empowered journey toward human-like understanding. It is crucial in preparing raw data for AI and machine learning training so that algorithms can understand what they read, see, hear, or watch. In practice, it involves assigning a tag to each piece of data, whether images, text, audio, or video. Without such labels, the records fed into the system would be like a foreign language for a real person: unintelligible, unusable and inefficient. In other words, data labelling turns chaos into the first level of clarity.

How does data labelling work in practice?
Data labelling typically answers the question: “What is this?” For example, in an image dataset, each photo might be labelled as “cat,” “dog,” or “car.” In text, a sentence could be labelled as “positive” or “negative” for sentiment analysis. This information provides the basic structure that allows AI systems to properly categorise new, unseen data.
Accuracy and consistency are at the heart of effective data labelling. The resulting AI model may produce unreliable or biased outcomes if labels are incorrect or applied inconsistently. As data volumes grow, the task can become increasingly complex and time-consuming, often requiring domain expertise and careful project management to maintain high standards.
Therefore, many data labelling processes now combine human expertise with automation to meet these challenges. AI-assisted tools can suggest labels, which human annotators then review and refine. This hybrid approach helps to balance efficiency with the need for precision and oversight.
Labelled vs Unlabelled Data. What’s the Real Difference?
Unlabelled data is like raw ingredients scattered on a table, full of potential but meaningless on their own. On the other hand, labelled data is that ingredient carefully tagged and prepped, ready for the AI chef to make wise decisions. Simply put, unlabelled data is the question, while labelled data is the answer.
What is Data Annotation
While data labelling assigns basic categories that help AI models differentiate between types of information, annotation goes much further. It enriches each data point with additional context and detail, allowing algorithms to grasp what something is and its unique characteristics. By marking, describing, and highlighting specific features within the record, annotation enables AI systems to interpret subtle nuances and interact with the world in a way that more closely mirrors human understanding. This deeper insight empowers AI to move beyond simple identification and towards more sophisticated, context-aware decision-making.
How does data annotation work in practice?
Data annotation is about adding meaning to data so AI can recognise things, how they relate to their surroundings, and why they are important in context. For instance, annotators might tag call recordings in customer support applications where a client’s tone changes or background noise becomes noticeable.
By marking these moments, they help AI systems transcribe and analyse conversations with greater accuracy and contextual awareness. This allows AI to pick up on subtleties like frustration, sarcasm or urgency. These factors are crucial for delivering relevant, personalised responses in CX.
Nevertheless, the practical side of data annotation is both intricate and demanding. Projects often require a blend of skilled human annotators, domain expertise, and advanced tools. Precision is key since even small errors can lead to AI misunderstandings. Ultimately, it is a meticulous process but essential to unlocking the full potential of artificial intelligence in real-world applications.

Key Differences Between Annotation and Labelling
While data annotation and labelling services are closely related and sometimes used interchangeably, they serve distinct purposes and involve different levels of detail. Data labelling is ideal for straightforward classification tasks like social media moderation, basic image sorting, or sentiment analysis. On the other hand, annotation is critical for advanced applications in sectors such as autonomous vehicles, healthcare diagnostics, and legal document processing, where understanding context, relationships, and fine-grained details matter for optimal AI performance.
| Aspect | Data Labelling | Data Annotation |
|---|
| Purpose | Assigns clear, predefined tags so AI can recognise and sort data. | Adds deeper meaning by providing context, attributes, and relationships. |
| Process | Straightforward and repetitive — each data point is tagged with a simple label. | Involves detailed interpretation, often adding multiple layers per data point. |
| Tools Used | Simple tools optimised for speed and high-volume tagging. | Advanced platforms for complex markups, segmentation, or metadata layering. |
| Who Performs It | Typically handled by generalists or large outsourced teams. | Requires subject-matter experts, often in smaller, specialised teams. |
| Depth of Insight | Enables basic classification and structured input. | Supports nuanced understanding — tone, sentiment, relationships, and spatial cues. |
| Best Fit For | Large-scale, consistent tasks where efficiency is key. | Projects needing precision, contextual awareness, and adaptability. |
| Strategic Value | Builds a solid foundation for AI in controlled, predictable use cases. | Prepares AI for complex, real-world scenarios that require adaptive reasoning. |
Data Labelling vs. Data Annotation: Clearing Up the Confusion
In artificial intelligence and machine learning projects, data labelling and data annotation are often used interchangeably. This overlap in language, while seemingly minor, can lead to significant misalignment between stakeholders, especially when it comes to planning, budgeting, or outsourcing data-related tasks. The confusion typically arises from inconsistent industry terminology and the commercial tendency to simplify or generalise complex processes for easy communication. As a result, many service providers and internal teams blur the distinction between simple tagging and more nuanced contextual enrichment, creating the perfect conditions for misunderstanding.

Why Terminology Matters More Than You Think
The consequences of this confusion tend to surface during execution. Clients expecting basic labelling may be surprised that a project requires more detailed work.
At the same time, teams assuming comprehensive annotation might underdeliver when the scope is limited to high-level tagging. This mismatch often leads to project delays, inflated costs, and underperformance against key benchmarks.
To avoid these outcomes, it is essential to define requirements clearly from the outset and ensure that all stakeholders understand the terminology.
Labelling should be understood as a subset of annotation, one specific activity within a broader, more layered process.
Recognising this structure allows teams to select appropriate tools, establish realistic timelines, and engage partners who truly grasp the complexity of data preparation.
Ensuring Reliability and Customer Advocacy
When the confusion originates internally within the company, the risks are magnified.
Ambiguity in definitions can lead to poorly scoped initiatives, misguided vendor selection, and workflows that are either inefficient or unnecessarily complex.
Teams may invest in tools that do not fit the real requirements or allocate resources in the wrong areas, resulting in avoidable waste.
In some cases, these foundational missteps compromise the models the data is meant to support, leading to flawed outputs, failed pilot programmes, or damage to the organisation’s reputation.
For companies that pride themselves on being data-driven, this misalignment undermines credibility and weakens long-term strategic potential.

Ultimately, success in AI and machine learning does not rest solely on the quality of the data. It also depends on the clarity of communication surrounding it. When everyone involved understands what is actually required and what the terms mean, the chances of a smooth, effective project increase dramatically. In this context, clarity is not simply helpful but a genuine competitive advantage.
When Should You Outsource Data Annotation or Labelling?
In the fast-paced world of AI development, the quality and scalability of data labelling and annotation services can determine the success of your models. As projects grow more complex and time-sensitive, organisations must determine whether to keep this function in-house or engage external experts. This decision is not just operational but strategic.

Recognising the Right Moment
Key indicators often suggest when it is time to seek external support. These are resource bottlenecks, a lack of specialised expertise, or the need for scalability.
When internal teams are stretched thin, deadlines slip, or project demands surge unexpectedly, outsourcing offers relief.
It provides skilled annotators, advanced tools, and the operational flexibility to meet changing requirements.
Additionally, professional providers ensure quality and consistency through established control processes, helping maintain the integrity of your datasets and, in turn, the reliability of your AI models.
Beyond the Immediate Need
Beyond efficiency, outsourcing brings broader strategic advantages. These include access to a wider talent pool, reduced overhead costs, and cross-industry insights that can elevate the relevance of your data.
However, success hinges on the decision to outsource and how the partnership is built.
It begins with strategic alignment and is steered by the Operations Manager, whose choices shape whether the external team becomes a true extension of your brand.
When done right, outsourcing becomes more than a solution. It is a force multiplier for innovation and a competitive edge. It turns operational support into a strategic advantage, quietly powering the breakthroughs your competitors can’t replicate.

Choosing the Right Partner
Selecting the right partner for data annotation or labelling is pivotal but challenging. It can significantly influence the success of the AI-driven initiatives. With machine learning projects’ growing complexity and scale, aligning with a provider that truly understands your needs is more important than ever.

What Makes a Reliable Partner?
Choosing a data annotation or labelling partner is more than simply picking a vendor. It is about finding a team that can align with your vision, handle your data responsibly, and scale alongside your ambitions.
A reliable BPO firm should demonstrate a strong track record in your industry, with proven experience handling much the same data type and delivering on similar project scopes. This familiarity reduces the risk of miscommunication and ensures a smoother workflow.
Technical capability is another critical marker.
The right BPO partner should use secure, modern platforms that support your data formats, integrate seamlessly into your existing systems, and offer features like version control and audit trails. Combined with multi-layered quality assurance and transparent accuracy metrics, these tools lay the groundwork for consistent, trustworthy output.
Adapting to Complexity and Scale
As AI projects evolve, so do their data demands. Scalability and flexibility are non-negotiable qualities in a strategic partner. Whether you’re managing a one-off initiative or an ongoing program with fluctuating workloads, your provider should be able to scale resources up or down quickly while maintaining performance.
Their ability to adapt without compromising on quality or deadlines clearly shows operational maturity. Domain expertise adds another layer of value, especially for projects in regulated or highly specialised industries.
A partner who understands the context, from medical terminology to legal nuances or geographic-specific cues, will annotate data with the level of depth and relevance your models require. This accuracy is essential for training AI systems to perform reliably in the real world.


Trust, Transparency, and Long-Term Success
Beyond technical fit and scalability, the strength of your partnership often hinges on communication and trust. A dependable provider will offer clear, transparent communication, responsive support, and dedicated project management. You should feel confident that your BPO provider understands your goals, provides honest timelines, and actively collaborates with your team.
Data security and compliance must also be central to your selection process. The right partner will be well-versed in industry data privacy and protection standards and will handle your sensitive or regulated data carefully. Compliance should never be an afterthought, whether your project involves personal information, proprietary datasets, or GDPR-sensitive materials.
A thoughtful, deliberate selection process, potentially starting with a pilot project, will help confirm that your chosen vendor meets all expectations. When well matched, such a company does not just execute tasks. They contribute strategic value, accelerate delivery, and elevate the overall success of your AI initiatives.
When should a BPO partner be on your company radar?
When internal teams face mounting data volumes, shifting project demands, or needing specialised expertise, a BPO partner becomes more than a support option. Whether you are struggling with scalability, quality control, or tight deadlines, outsourcing to a trusted provider can streamline workflows, boost accuracy, and free your core team to focus on innovation. If precision, speed, and flexibility are critical to your AI goals, a BPO partner should be firmly on your radar.
Conclusion
At the heart of every successful AI project is one often overlooked truth: intelligence does not emerge from data alone. It is built on how well that information is understood, structured, and contextualised. That is the real power of labelling and annotation. Not just checking boxes but shaping meaning. In a world obsessed with automation, it is easy to forget that human insight still lies at the foundation of machine learning. Get that right, and everything else, including performance, scalability, and impact, starts to click. Getting it wrong and even the smartest algorithm becomes a costly guessing game. So, whether you are refining chatbots or training autonomous systems, do not just feed your AI. Teach it well.
FAQ Section
1. Why can’t AI systems learn from raw data without labelling or annotation?
AI doesn’t come with a built-in understanding of the world. Raw data is often disorganised and lacks clarity. Without structured guidance through labelling and annotation, algorithms struggle to detect patterns or make reliable decisions. These preparatory steps act like a curriculum that “trains” the AI to interpret and respond meaningfully.
2. How do labelling and annotation differ in terms of complexity and purpose?
Labelling is typically a high-level categorisation task, such as tagging emails as “spam” or “not spam.” Annotation digs deeper, providing context, relationships, or emotional tone, such as identifying sarcasm in a sentence or marking specific objects within an image. Annotation requires more expertise and yields more nuanced insights.
3. What risks do companies face if they misunderstand the distinction between labelling and annotation?
Confusion around terminology can lead to mismatched expectations. A project scoped as simple labelling may require detailed annotation, resulting in missed deadlines, budget overruns, or underperforming models. Clear definitions upfront help avoid these setbacks and ensure teams are aligned on project goals.
4. When is outsourcing data preparation a smart move?
Outsourcing becomes valuable when internal teams are overstretched, timelines tighten, or tasks require specialised skills. External providers can offer scale, consistency, and quality assurance, making them essential for fast-paced or complex projects. The key is choosing a partner that aligns with your technical needs and long-term vision.
5. What should I look for in a data annotation or labelling provider?
A capable partner will bring domain expertise, secure and flexible tools, and a history of successful delivery in your sector. Look for adaptability, a strong quality control process, and the ability to scale as your needs evolve. Transparency, clear communication, and contextual understanding set the best providers apart.


